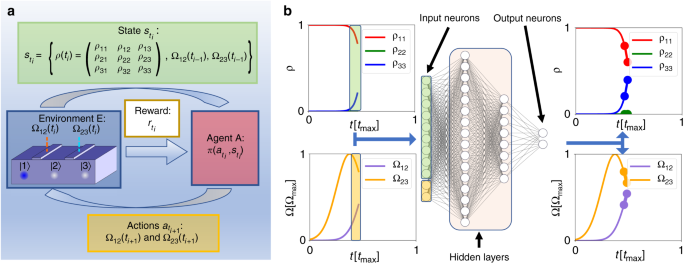
Η βαθιά αρχιτεκτονική μάθησης ενίσχυση για τον έλεγχο της συνεκτικής μεταφοράς από αδιαβατική διέσμα. Η περιφέρεια Ε μπορεί να αντιπροσωπεύεται από μια γραμμική σειρά τεσσάρων τεμαχίων, με ποσοστά ανοίγματος των σηράγγων ελέγχεται από δύο πύλες που υποδεικνύονται από Ω 12 και Ω 23 . Σε κάθε χρονικό βήμα, το περιβάλλον DRL μπορεί να μοντελοποιηθεί με μια μήτρα 3 × 3 πυκνότητας που χρησιμοποιείται ως μία παρατήρηση εισόδου (η κατάσταση) από τον παράγοντα Α Με τη σειρά του, ο παράγοντας Α χρησιμοποιεί την παρατήρηση για να επιλέξει την ενέργεια στο επόμενο χρονικό βήμα ακολουθώντας μια πολιτικήπ( 𝑎𝑡𝑖| 𝑠𝑡𝑖). Η δράση αυτή φέρνει την Ε σε μια νέα κατάστασηρ𝑡𝑖 + 1= ρ ( 𝑡 + Δ 𝑡 ). Κάθε δράση τιμωρείται ή ανταμείβεται με ένα πραγματικών τιμών ανταμοιβή , που υποδεικνύεται από r t . β Αντιπρόσωπος Ένα αντιπροσωπεύει ένα νευρικό δίκτυο τεσσάρων στρωμάτων, το οποίο ενεργεί ως πολιτική π . Σε κάθε χρονικό βήμα, το δίκτυο δέχεται τις 3 × 3 = 9 πραγματικές τιμές που σχετίζονται με τις ατελείς τιμές των στοιχείων της πυκνότητας μήτρας ρ και τις δύο τιμές του παλμού ελέγχου πύλης Ω 12 και Ω 23 για ένα σύνολο 11 νευρώνων στο στρώμα εισόδου. Στη συνέχεια, ο παράγοντας υπολογίζει την πολιτική πκαι εξάγει τις τιμές των δύο παλμών που θα εφαρμοστούν σε πύλες ελέγχου φράγματος στο βήμα την επόμενη φορά ( β , Κάτω δεξιά). Τα σημεία έναρξης και λήξης των επισημασμένων τμημάτων μπορούν να συνδέονται με διαφορετικές λειτουργίες του χρόνου, όπως το κινητό μέσο ή μια λειτουργία spline για να εξομαλύνει το βήμα λειτουργίας που παράγεται από τα διακριτά χρονικά βήματα. Τέλος, η φυσική προσομοίωση της κβαντικής συστοιχίας dot φέρνει το σύστημα σε μια νέα κατάσταση με την ενημέρωση του πίνακα πυκνότητας αναλόγως και επιστρέφει r t στον παράγοντα. Σε t = t max , το σύστημα φτάνει στο τελικό στάδιο ( k = Ν ), και οι άκρα της προσομοίωσης

 APOLLO ATLAS CASSINI CERN CMS Curiosity DAWN DNA EINSTEIN FERMI Feynman Hawking Hubble KEPLER LHC LIGO NASA New Horizons NOBEL Opportunity Rosetta Schrödinger VOYAGER ΑΙΝΣΤΑΙΝ ΑΚΤΙΝΕΣ ΓΑΜΑ ΑΝΤΙΥΛΗ ΑΠΟΛΛΩΝ ΑΡΗΣ ΑΣΤΕΡΕΣ ΝΕΤΡΟΝΙΩΝ ΑΣΤΕΡΟΕΙΔΕΙΣ ΑΦΡΟΔΙΤΗ ΒΑΡΥΤΙΚΑ ΚΥΜΑΤΑ ΓΑΛΑΞΙΑΣ ΓΑΛΑΞΙΕΣ ΓΡΑΦΕΝΙΟ ΔΙΑΣ ΔΙΑΤΤΟΝΤΕΣ ΔΟΡΥΦΟΡΟΙ ΕΓΚΕΦΑΛΟΣ ΕΚΛΕΙΨΗ ΗΛΙΟΥ ΕΠΙΤΑΧΥΝΤΕΣ ΕΡΜΗΣ Η ΑΣΚΗΣΗ ΤΗΣ ΕΒΔΟΜΑΔΑΣ ΗΛΕΚΤΡΙΣΜΟΣ ΗΛΙΟΣ ΘΕΩΡΙΑ ΧΟΡΔΩΝ ΚΒΑΝΤΙΚΟΙ ΥΠΟΛΟΓΙΣΤΕΣ ΚΕΠΛΕΡ ΚΟΜΗΤΕΣ ΚΟΣΜΙΚΗ ΑΚΤΙΝΟΒΟΛΙΑ ΥΠΟΒΑΘΡΟΥ ΚΡΙΜΙΖΗΣ ΚΡΟΝΟΣ ΚΥΜΑΤΑ ΜΑΓΝΗΤΙΚΟ ΠΕΔΙΟ ΜΕΓΑΛΗ ΕΚΡΗΞΗ ΜΟΝΑΔΕΣ ΝΑΝΟΤΕΧΝΟΛΟΓΙΑ ΝΕΤΡΙΝΟ ΝΟΜΠΕΛ ΟΠΤΙΚΗ ΣΥΣΤΗΜΑ ΠΛΑΝΗΤΕΣ ΠΛΗΘΩΡΙΣΜΟΣ ΠΛΟΥΤΩΝ ΣΕΛΗΝΗ ΣΙΜΟΠΟΥΛΟΣ ΤΑΧΥΤΗΤΑ ΦΩΤΟΣ ΤΕΧΝΗΤΗ ΝΟΗΜΟΣΥΝΗ ΤΗΛΕΣΚΟΠΙΑ ΤΙΤΑΝΑΣ ΧΡΟΝΟΣ ΧΩΡΟΣ
APOLLO ATLAS CASSINI CERN CMS Curiosity DAWN DNA EINSTEIN FERMI Feynman Hawking Hubble KEPLER LHC LIGO NASA New Horizons NOBEL Opportunity Rosetta Schrödinger VOYAGER ΑΙΝΣΤΑΙΝ ΑΚΤΙΝΕΣ ΓΑΜΑ ΑΝΤΙΥΛΗ ΑΠΟΛΛΩΝ ΑΡΗΣ ΑΣΤΕΡΕΣ ΝΕΤΡΟΝΙΩΝ ΑΣΤΕΡΟΕΙΔΕΙΣ ΑΦΡΟΔΙΤΗ ΒΑΡΥΤΙΚΑ ΚΥΜΑΤΑ ΓΑΛΑΞΙΑΣ ΓΑΛΑΞΙΕΣ ΓΡΑΦΕΝΙΟ ΔΙΑΣ ΔΙΑΤΤΟΝΤΕΣ ΔΟΡΥΦΟΡΟΙ ΕΓΚΕΦΑΛΟΣ ΕΚΛΕΙΨΗ ΗΛΙΟΥ ΕΠΙΤΑΧΥΝΤΕΣ ΕΡΜΗΣ Η ΑΣΚΗΣΗ ΤΗΣ ΕΒΔΟΜΑΔΑΣ ΗΛΕΚΤΡΙΣΜΟΣ ΗΛΙΟΣ ΘΕΩΡΙΑ ΧΟΡΔΩΝ ΚΒΑΝΤΙΚΟΙ ΥΠΟΛΟΓΙΣΤΕΣ ΚΕΠΛΕΡ ΚΟΜΗΤΕΣ ΚΟΣΜΙΚΗ ΑΚΤΙΝΟΒΟΛΙΑ ΥΠΟΒΑΘΡΟΥ ΚΡΙΜΙΖΗΣ ΚΡΟΝΟΣ ΚΥΜΑΤΑ ΜΑΓΝΗΤΙΚΟ ΠΕΔΙΟ ΜΕΓΑΛΗ ΕΚΡΗΞΗ ΜΟΝΑΔΕΣ ΝΑΝΟΤΕΧΝΟΛΟΓΙΑ ΝΕΤΡΙΝΟ ΝΟΜΠΕΛ ΟΠΤΙΚΗ ΣΥΣΤΗΜΑ ΠΛΑΝΗΤΕΣ ΠΛΗΘΩΡΙΣΜΟΣ ΠΛΟΥΤΩΝ ΣΕΛΗΝΗ ΣΙΜΟΠΟΥΛΟΣ ΤΑΧΥΤΗΤΑ ΦΩΤΟΣ ΤΕΧΝΗΤΗ ΝΟΗΜΟΣΥΝΗ ΤΗΛΕΣΚΟΠΙΑ ΤΙΤΑΝΑΣ ΧΡΟΝΟΣ ΧΩΡΟΣ
No comments:
Post a Comment